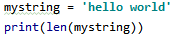
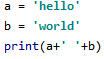
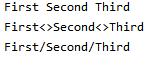
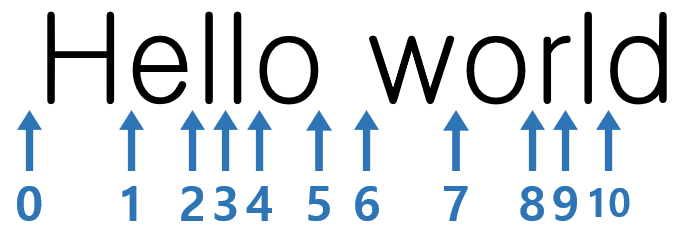
* 출처 : https://github.com/lsi8546/Wine
numpy, pandas, seaborn,
mat plot lib을 import합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
%matplotlib inline
# csv 파일을 wines에 읽어옴
wines = pd.read_csv('wine_dataset.csv')
wines
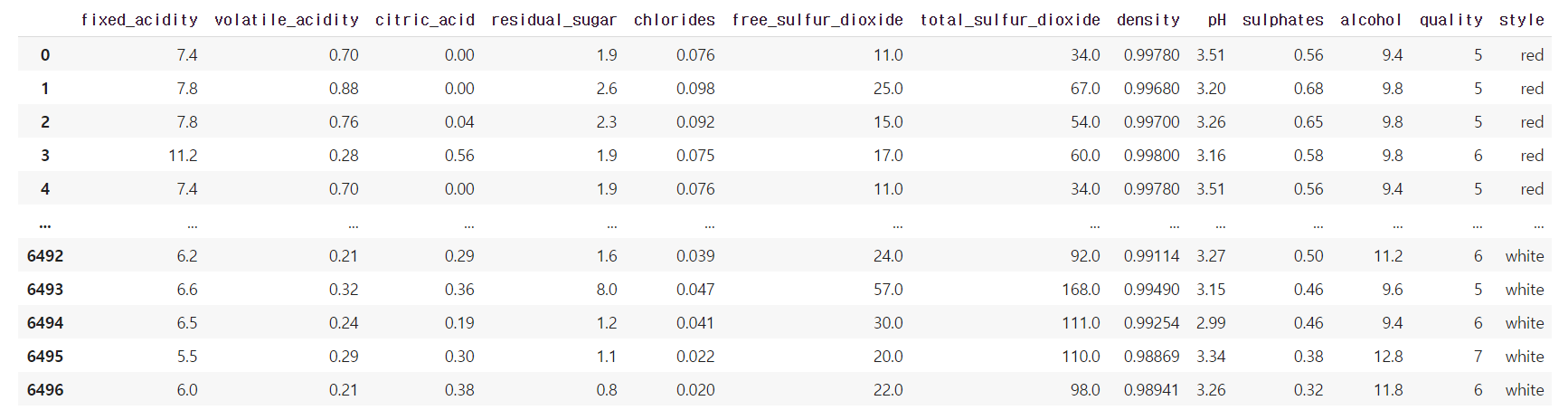
파일을 읽어온 wines의 style 칼럼의
value를 count 합니다.
normalize=True를 통해 그 값을 0~1 사이의 수치로 표현합니다.
data = wines["style"].value_counts(normalize=True)
data

white wine이 75%,
red wine이 25%로 구성되어 있다는 것을 알 수 있습니다.
scaling을 했더니 정확한 값이 나오지 않아서 (혹시 이유 아시는 분 댓글 부탁드립니다!)
그냥 wines_scale에 wines를 copy했습니다.
#Scaling the continuos variables
wines_scale = wines.copy()
# scaler = preprocessing.StandardScaler()
# columns = wines.columns[0:12]
# wines_scale[columns] = scaler.fit_transform(wines_scale[columns])
# wines_scale.head()
파일의 'style' 칼럼만 읽어옵니다
# label_encoder = preprocessing.LabelEncoder()
le = wines_scale['style']
print(le)

33%를 테스트 코드로 이용합니다.
(자료가 많아서 67%로 학습)
X : style 칼럼을 제외한 항목들
y : style 칼럼의 항목들
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(wines_scale.iloc[:,0:12], le, test_size=0.33, random_state=8)
#[0:12]는 0~11
X와 y를 출력해보겠습니다
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)

X_train : X_test = 4352 : 2145 가 거의 67:33
y_train : y_test 도 거의 67:33 인 것을 알 수 있습니다.
세 가지 모델을 이용했습니다.
* DecisionTreeClassifier
* RandomForestClassifier
* LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 결정트리, Random Forest, 로지스틱 회귀를 위한 사이킷런 Classifier 클래스 생성
dt_clf = DecisionTreeClassifier(random_state=11)
rf_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression()
# DecisionTreeClassifier 학습/예측/평가
dt_clf.fit(X_train , y_train)
dt_pred = dt_clf.predict(X_test)
print('DecisionTreeClassifier 정확도: {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
# RandomForestClassifier 학습/예측/평가
rf_clf.fit(X_train , y_train)
rf_pred = rf_clf.predict(X_test)
print('RandomForestClassifier 정확도:{0:.4f}'.format(accuracy_score(y_test, rf_pred)))
# LogisticRegression 학습/예측/평가
lr_clf.fit(X_train , y_train)
lr_pred = lr_clf.predict(X_test)
print('LogisticRegression 정확도: {0:.4f}'.format(accuracy_score(y_test, lr_pred)))

모델별로 정확도가 아주 높게 나오는 것을 알 수 있습니다.
[임의의 값으로 테스트]
기존 데이터 베이스에 없는 임의의 red wine 값을 넣었습니다.
my_wine = [[7.9,0.6,0.06,1.6,0.069,15,59,0.9964,3.3,0.46,9.4,5]]
예측한 값을 my_pred에 넣습니다. (rf_clf 모델이용)
my_pred = rf_clf.predict(my_wine)
my_pred
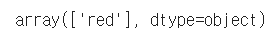
결과가 red로 잘 나오는 것을 확인할 수 있습니다 :)
* 이용 데이터
* 추가 테스트 해보고 싶을때
'파이썬' 카테고리의 다른 글
| [ Python ] 사칙연산 및 간단한 계산 (0) | 2021.03.08 |
|---|---|
| [ Python ] 파이썬 실행, 버전 확인, 윈도우 환경변수 확인, IDLE (0) | 2021.03.08 |
| 파이썬 패키지 ( numpy, pandas , seaborn) (2) | 2020.11.18 |
| [ML] numpy pandas 설치 (0) | 2020.11.14 |
| [Python_01] 문자열 관련 명령어 (0) | 2020.02.04 |